DeepSeek火爆出圈:全球首个复现OpenAI o1能力团队
AI导读:
DeepSeek通过纯粹的强化学习技术成功复现OpenAI o1能力,引发全球关注。其R1模型展示了深度思考的力量,人工智能领域迎来新震撼。文章探讨DeepSeek火爆出圈的原因及其对未来AI发展的影响。
自2025年1月底以来,Deepseek在全球范围内引发了广泛关注,成为业界内外热议的焦点。其独特的技术实力和创新成果,吸引了众多目光。
近日,中国基金报记者有幸专访了面壁智能的创始人兼首席科学家刘知远,请他深入剖析DeepSeek火爆出圈背后的原因。

在刘知远看来,OpenAI的o1模型如同引爆了一颗原子弹,但其并未透露实现这一壮举的秘方。而DeepSeek则可能是全球首个通过纯粹的强化学习技术成功复现OpenAI o1能力的团队。他们不仅开源了这一技术,还发布了相对详细的介绍,为人工智能行业的发展做出了重要贡献。
DeepSeek-R1的发布,让全世界见证了深度思考的力量,人工智能领域因此迎来了类似于2023年初ChatGPT时刻的震撼。人们深刻感受到,大模型的能力又迈上了一个新的台阶。
刘知远指出,人工智能大模型领域存在一个被称为“大模型密度定律”的现象,即模型的能力密度随时间呈指数级增强。自2023年以来,大模型的能力密度大约每100天翻一倍。这意味着,每过100天,我们只需一半的算力和一半的参数,就能实现相同的能力。
刘知远强调,我们正站在智能革命的门槛上,这一革命的高潮即将到来,这是既可期待又可触及的现实。
以下是此次专访的详细内容:
中国基金报:近期,DeepSeek在国内外备受瞩目,您认为其主要原因是什么?
刘知远:这主要得益于DeepSeek最近发布的R1模型,它具有极高的价值。该模型能够复现OpenAI o1的深度推理能力,这是其核心价值所在。由于OpenAI o1并未透露实现细节,我们不得不从零开始探索复现方法。而DeepSeek可能是全球首个通过纯粹的强化学习技术成功复现OpenAI o1能力的团队,并且他们通过开源和详细介绍,为行业发展做出了巨大贡献。
DeepSeek-R1的训练流程具有两大亮点或价值。首先,它创造性地基于DeepSeek V3基座模型,通过大规模强化学习技术,得到了一个纯粹通过强化学习增强的强推理模型——DeepSeek-R1-Zero。这在历史上是罕见的,因为很少有团队能成功将强化学习技术应用于大规模模型并实现大规模训练。其次,DeepSeek-R1的强化学习技术不仅局限于数学、算法代码等易提供奖励信号的领域,还能将强化学习带来的强推理能力泛化到其他领域。这也是用户在使用DeepSeek-R1进行写作等任务时,能感受到其强大深度思考能力的原因。
综上,DeepSeek-R1的贡献主要体现在两个方面:一是通过规则驱动的方法实现了大规模强化学习;二是通过深度推理SFT数据与通用SFT数据的混合微调,实现了推理能力的跨任务泛化。这使得DeepSeek-R1能够成功复现OpenAI o1的推理水平。

此外,由于DeepSeek-R1的开源,全世界都意识到了深度思考的威力。人工智能领域再次迎来了类似2023年初ChatGPT时刻的震撼。每个人都感受到大模型的能力又迈上了一个新的台阶。
然而,我们也需要理性看待DeepSeek-R1的意义。它在历史上更像2023年Meta的LLaMA模型,具有里程碑式的意义。
中国基金报:DeepSeek R1能够取得全球性成功的原因有哪些?
刘知远:这与OpenAI采用的策略有很大关系。OpenAI在发布o1后,首先选择不开源;其次,它将o1的深度思考过程隐藏起来;第三,o1的收费非常高。因此,全球范围内仅有限的人能通过o1感受到深度思考所带来的震撼。而DeepSeek R1则像2023年初的ChatGPT一样,让所有人真正感受到了这种震撼,这是其出圈的重要原因。
如果将DeepSeek发布的R1和之前的V3结合起来考虑,那么它的意义在于:在有限的算力资源支持下,通过强大的算法创新,突破了算力瓶颈。这表明在有限的算力下,人工智能公司也能做出具有全球意义的领先成果。这对中国AI的发展具有重要意义。
当然,我们也应看到,AI要真正赋能全人类,让每个人都能用得上、用得起大模型和通用人工智能,高效性是一个重要命题。这也是DeepSeek-V3和R1带给我们的另一个重要启示。追求高效性是人工智能发展的内在使命和需求。
回顾上一次科技革命——信息革命,其重要内核是计算芯片的发展。在过去的80年中,计算机从占据整个房间的大型设备,演变为如今每个人手边的手机、PC等小型计算设备。这些设备都能在非常小的体积内完成强大的计算能力。这一切都源于芯片行业在摩尔定律的指引下,不断推进芯片制程、提升芯片电路密度,从而实现计算设备的小型化和普惠化,推动算力的普及。这是我们追求高效性的内在需求。
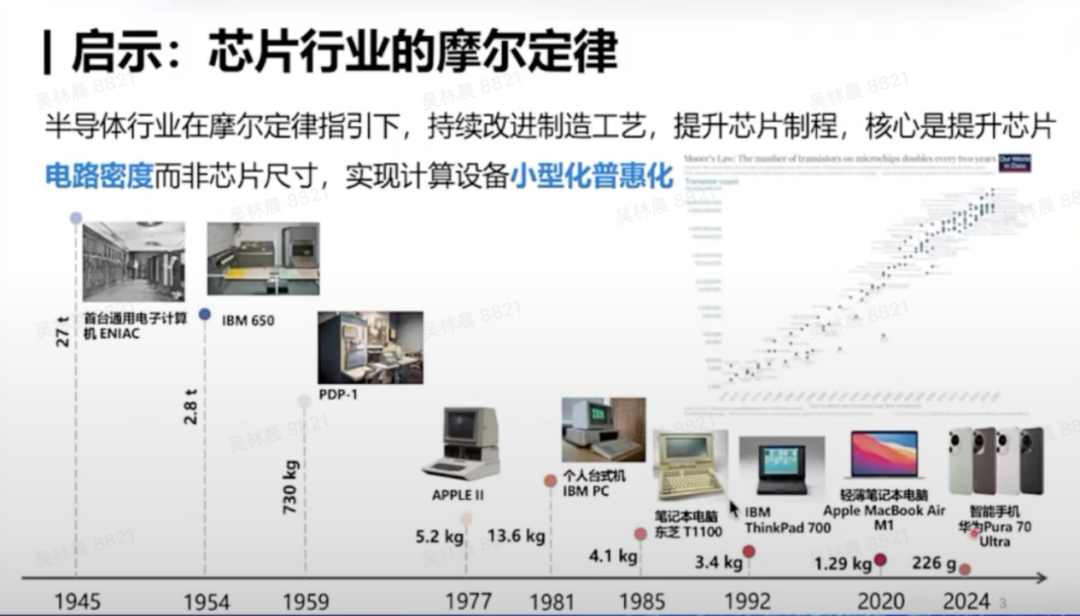
自2024年以来,我们特别强调要发展大模型的能力密度。过去几年,我们可以看到类似摩尔定律的现象:大模型的能力密度正随时间呈指数级增强。自2023年以来,大模型的能力密度大约每100天翻一倍。因此,面向未来,我们应不断追求更高的能力密度,努力以更低的成本(包括训练成本和计算成本)实现大模型的高效发展。
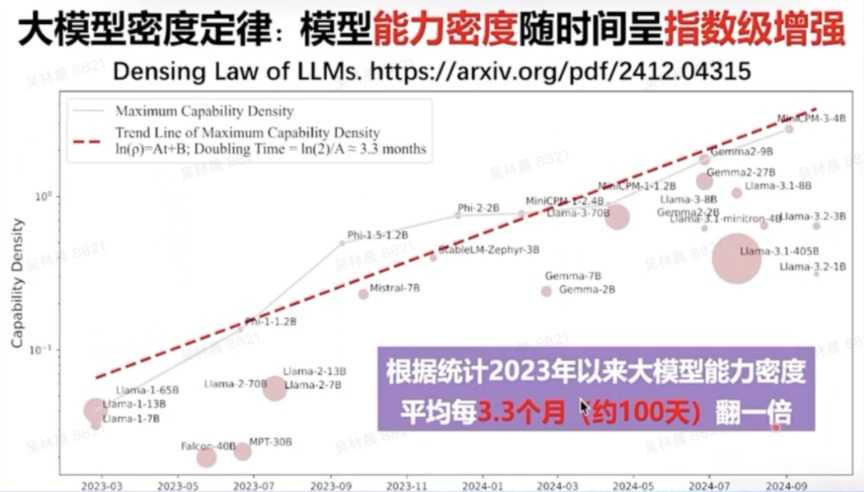
因此,我们认为智能革命将走过一个类似于信息革命的阶段,不断提高能力密度、降低计算成本。AI时代的核心引擎包括电力、算力以及大模型所代表的智力。这种密度定律应普遍存在。我们需要不断通过高质量、可持续的方式实现大模型的普惠,这是我们未来的发展方向。
面向未来,人工智能有三大主战场,目标都是让通用人工智能达到顶尖水平。首先,我们要探索人工智能的科学化技术方案,实现更科学、更高效的人工智能实现方式。其次,我们要实现计算系统的智能化,能够在计算层面以更低的成本、更通用地将大模型应用于各个领域。第三,我们也要在各个领域探索人工智能的广谱化应用。
最后,DeepSeek还让我们看到,即使资源有限,我们依然能够取得重大胜利。我们即将迎来意义深远的智能革命时代,其高潮即将到来,这是既可期待又可触及的现实。
中国基金报:DeepSeek-R1在这个时间点出现并如此出圈,是一种偶然还是具有某种必然性?
刘知远:它具有一定的必然性。2024年,很多投资人甚至一些不从事人工智能的人都曾向我提问:中美人工智能发展的差距是在变大还是变小。我当时表示,中国正在快速追赶,与美国最先进的技术之间的差距在逐渐缩小。尽管我们仍面临一些限制,但这种追赶是显而易见的。
自2023年初ChatGPT和GPT-4发布后,国内团队复现这两个版本的模型大概花了一年时间。2023年底,国内团队复现了ChatGPT水平的模型能力;去年四五月份,一线团队复现了GPT-4水平的能力。但此后,像Sora、GPT-4o的模型,国内团队大概半年内就可以完成复现。这意味着,o1的模型能力,国内团队在半年左右复现是可预期的。DeepSeek的价值不仅在于能够复现,还在于能够更快、以更低成本、更高效地完成工作。从这个角度看,我认为DeepSeek-R1现在出现有一定的必然性。
(文章来源:中国基金报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。




